PinnedCarla MartinsinCodeXExtreme Imbalanced Data — The Worst Data Scientist NightmareAnd the Accuracy TrapJun 17, 20221Jun 17, 20221
PinnedCarla MartinsSetting MacBook ARM processor for Data Science and Machine LearningTutorial for M1, M1 Pro, M1 Max and M2Aug 2, 2022Aug 2, 2022
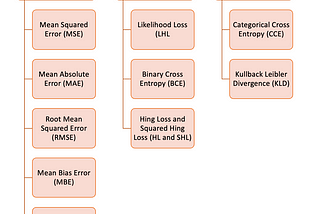
PinnedCarla MartinsinTowards AI10 Commonly Used Loss Functions Explained with Python CodeUnderstanding Loss Functions in Machine LearningAug 17, 2022Aug 17, 2022
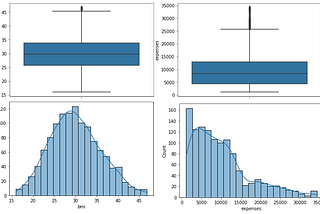
PinnedCarla MartinsinTowards AIHow to Detect Outliers Using Visualization Tools and Statistical MethodsWith Python codeSep 9, 20222Sep 9, 20222
PinnedCarla MartinsinDev GeniusHow I created my own Data Science jobStarting from Health Technology backgroundNov 25, 20213Nov 25, 20213
Carla Martins(19) OPTIMIZATION: AdaDelta — Stability and AdaptabilityAn alternative algorithm when ADAGRAD and RMSprop don’t have the necessary stabilityJul 15Jul 15
Carla Martins(18) OPTIMIZATION: Root Mean Squared Propagation or RMSpropPreventing ADAGRAD learning rate from decreasing to rapidlyJun 181Jun 181
Carla Martins(17) OPTIMIZATION: Adaptive Gradient Algorithm or ADAGRADAdapting the learning rate for each parameterMay 18May 18
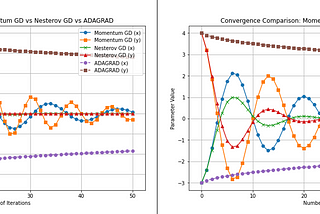
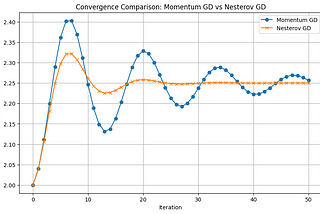
Carla Martins(16) OPTIMIZATION: Nesterov Momentum or Nesterov Accelerated Gradient (NAG)Improving Momentum Gradient DescentMay 9May 9
Carla Martins(15) OPTIMIZATION: Momentum Gradient DescentAnother way to improve Gradient Descent convergenceApr 11Apr 11